Evaluation in Arena#
Docker Container: Base (see Installation for more details)
./docker/run_docker.sh
Once inside the container, set the models directory:
export MODELS_DIR=/models/isaaclab_arena/dexsuite_lift
mkdir -p $MODELS_DIR
This step evaluates a checkpoint using Arena’s dexsuite_lift environment.
Pass --presets newton to use Newton physics (recommended when the checkpoint
was trained with Newton).
Download Pre-trained Model (skip training)
hf download \
nvidia/Arena-Dexsuite-Lift-RL-Newton-Task \
--local-dir $MODELS_DIR
After downloading, the checkpoint is at:
$MODELS_DIR/model_14999.pt
Note
If you trained locally (see Policy Training (Isaac Lab)), your checkpoints are at:
logs/rsl_rl/dexsuite_kuka_allegro/<timestamp>/model_<iter>.pt
Replace the checkpoint paths in the examples below accordingly.
Single Environment Evaluation#
python isaaclab_arena/evaluation/policy_runner.py \
--viz newton \
--presets newton \
--policy_type rsl_rl \
--num_steps 800 \
--checkpoint_path $MODELS_DIR/model_14999.pt \
dexsuite_lift
At the end of the run, metrics are printed to the console:
Metrics: {'success_rate': 0.75, 'num_episodes': 12}
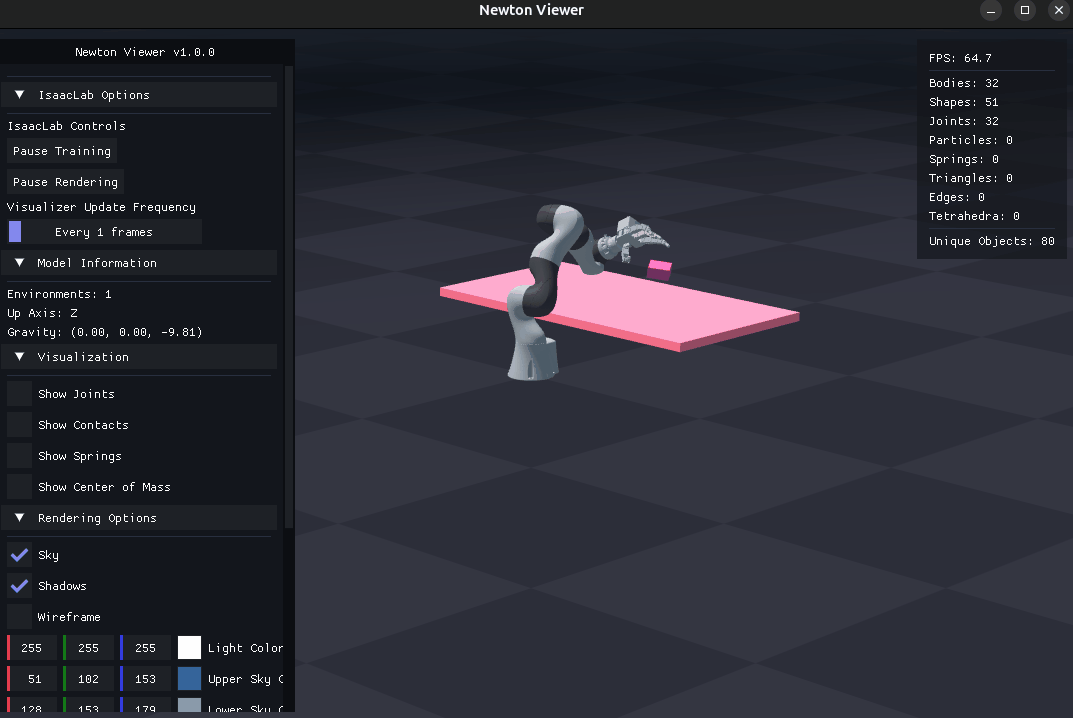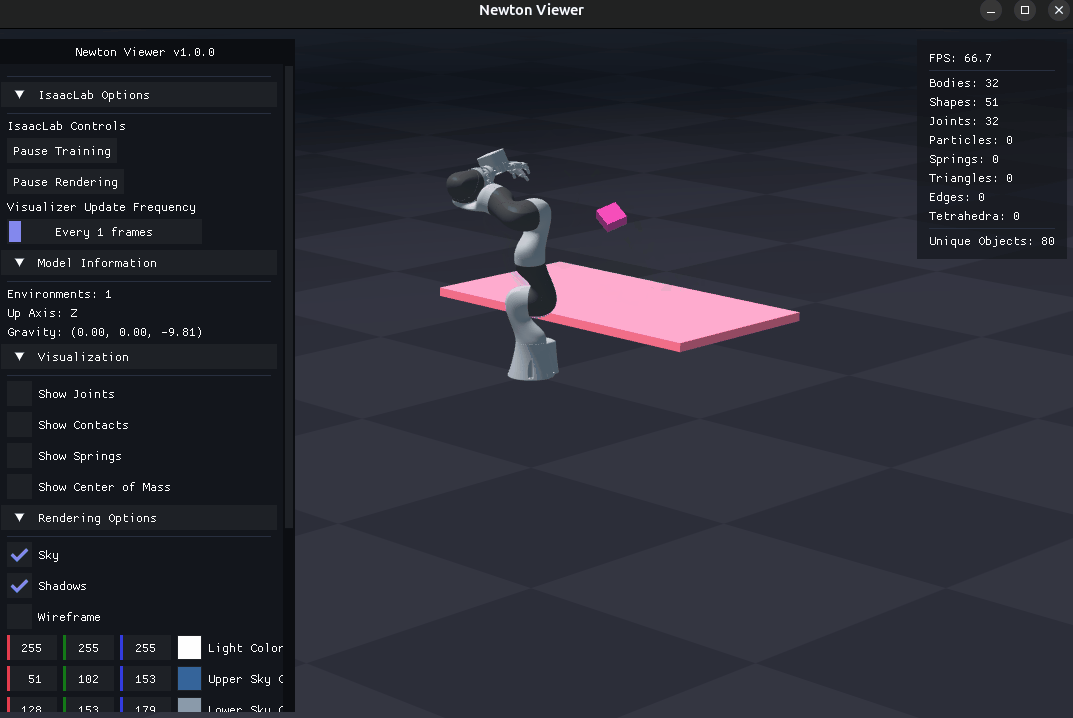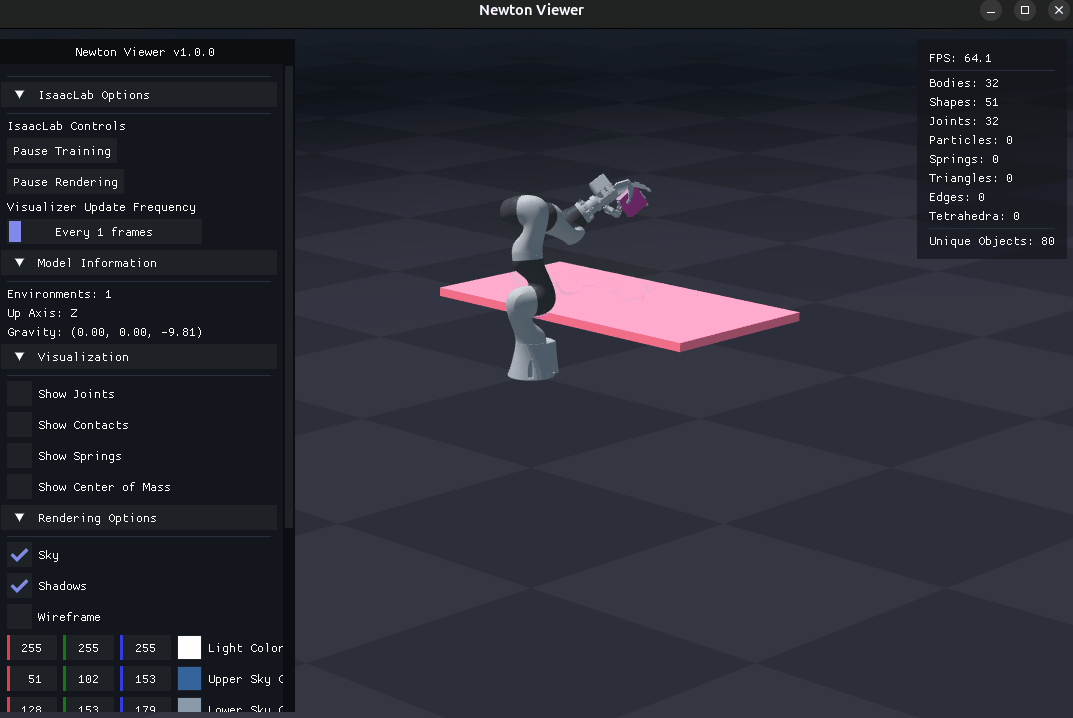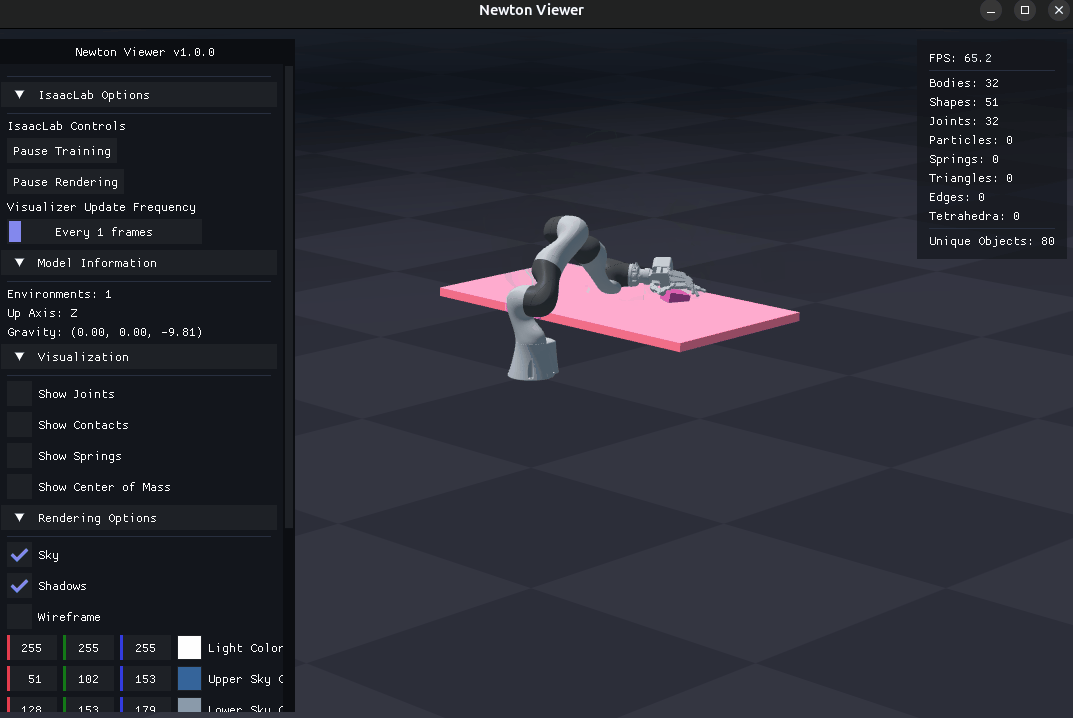
Tip
You can also evaluate a Newton-trained model using PhysX:
python isaaclab_arena/evaluation/policy_runner.py \
--viz kit \
--policy_type rsl_rl \
--num_steps 800 \
--checkpoint_path $MODELS_DIR/model_14999.pt \
dexsuite_lift
However, the model behaviour may differ significantly when training and evaluation use different physics backends. The above model, which was trained with Newton, fails to grasp or lift the cube completely when evaluated with PhysX.
Parallel Environment Evaluation#
For statistically significant results, run across many environments in parallel:
python isaaclab_arena/evaluation/policy_runner.py \
--presets newton \
--policy_type rsl_rl \
--num_steps 5000 \
--num_envs 64 \
--env_spacing 3 \
--checkpoint_path $MODELS_DIR/model_14999.pt \
dexsuite_lift
Metrics: {'success_rate': 0.72, 'num_episodes': 320}
Batch Evaluation#
To evaluate multiple checkpoints in sequence, use experiment_runner.py with a
JSON config.
1. Create an evaluation config
Create a file eval_config.json:
{
"jobs": [
{
"name": "dexsuite_lift_7500",
"arena_env_args": {
"environment": "dexsuite_lift",
"num_envs": 64,
"env_spacing": 3
},
"num_steps": 5000,
"policy_type": "rsl_rl",
"policy_config_dict": {
"checkpoint_path": "models/isaaclab_arena/dexsuite_lift/model_7500.pt"
}
},
{
"name": "dexsuite_lift_14999",
"arena_env_args": {
"environment": "dexsuite_lift",
"num_envs": 64,
"env_spacing": 3
},
"num_steps": 5000,
"policy_type": "rsl_rl",
"policy_config_dict": {
"checkpoint_path": "models/isaaclab_arena/dexsuite_lift/model_14999.pt"
}
}
]
}
2. Run
python isaaclab_arena/evaluation/experiment_runner.py --presets newton --eval_jobs_config eval_config.json
Understanding the Metrics#
The dexsuite_lift task reports:
success_rate: fraction of episodes where the object reached the target position within 5 cm tolerance.num_episodes: total number of completed episodes.